
Por qué los registros visualmente similares no siempre cuentan como duplicados
No todos los registros que se ven similares son duplicados. Este post explica por qué la similitud visual confunde a los equipos de CRM, cómo funciona realmente la lógica de asociación y qué revisar antes de cambiar las reglas de detección.

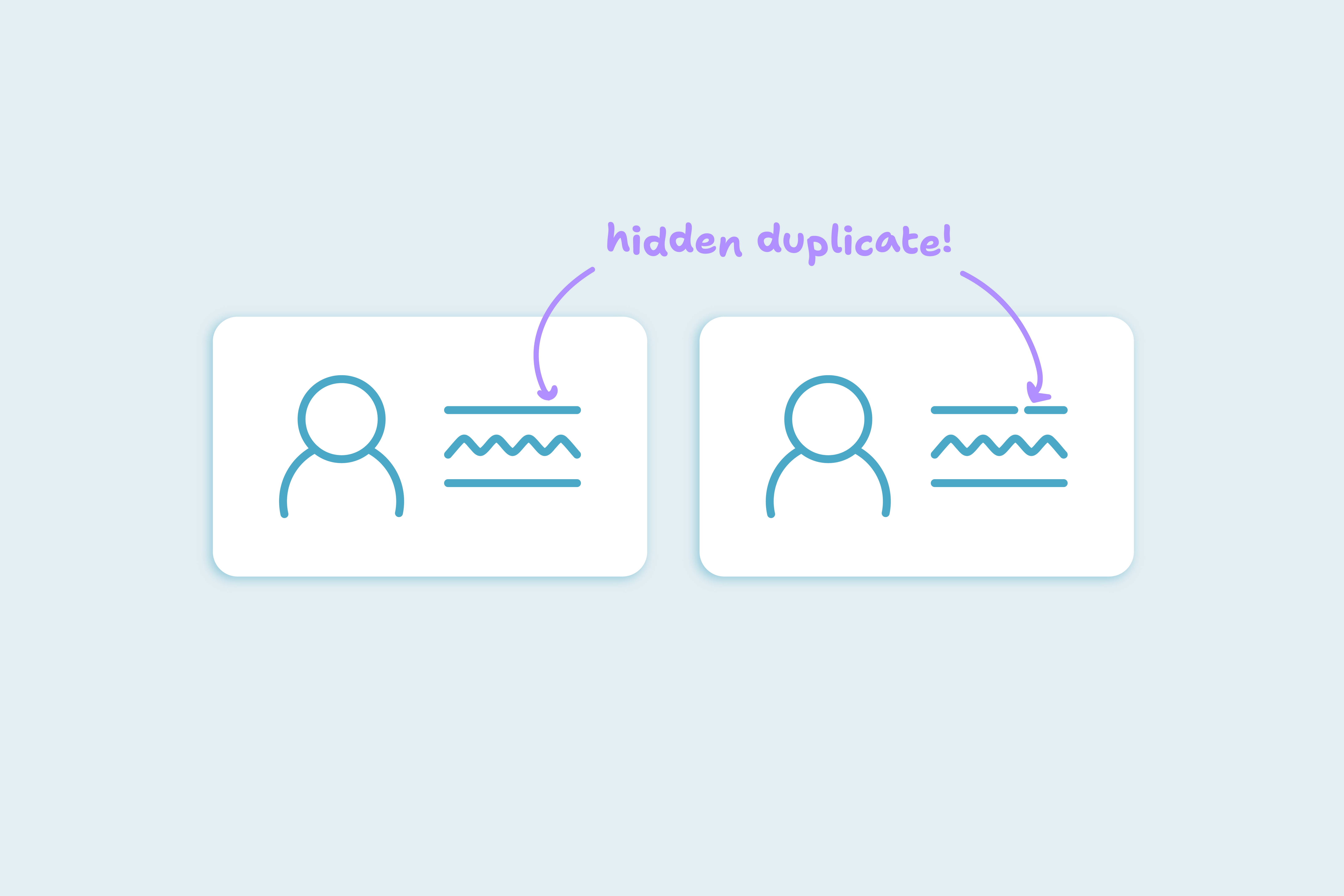
Que un contacto tenga el mismo nombre, empresa y dominio de correo no significa necesariamente que sea un duplicado. Cuando los equipos revisan registros de CRM manualmente, es común asumir que la similitud visual implica duplicados. Pero la lógica de combinación del CRM no ve los registros de esa forma, y no debería.
Un equipo de CRM aprendió esto después de asumir que una herramienta creaba duplicados después de cada combinación. Lo que descubrieron fue que, en realidad, ninguno de los registros era duplicado en absoluto.
Los duplicados no tratan del conflicto entre registros, sino de resolución. La lógica de combinación del CRM busca coincidencias basadas en campos específicos. Cuando los equipos esperan que "se vean iguales" para combinarse, se exponen a confusión, desconfianza y cambios innecesarios de reglas.
Los campos compartidos no son prueba de duplicación
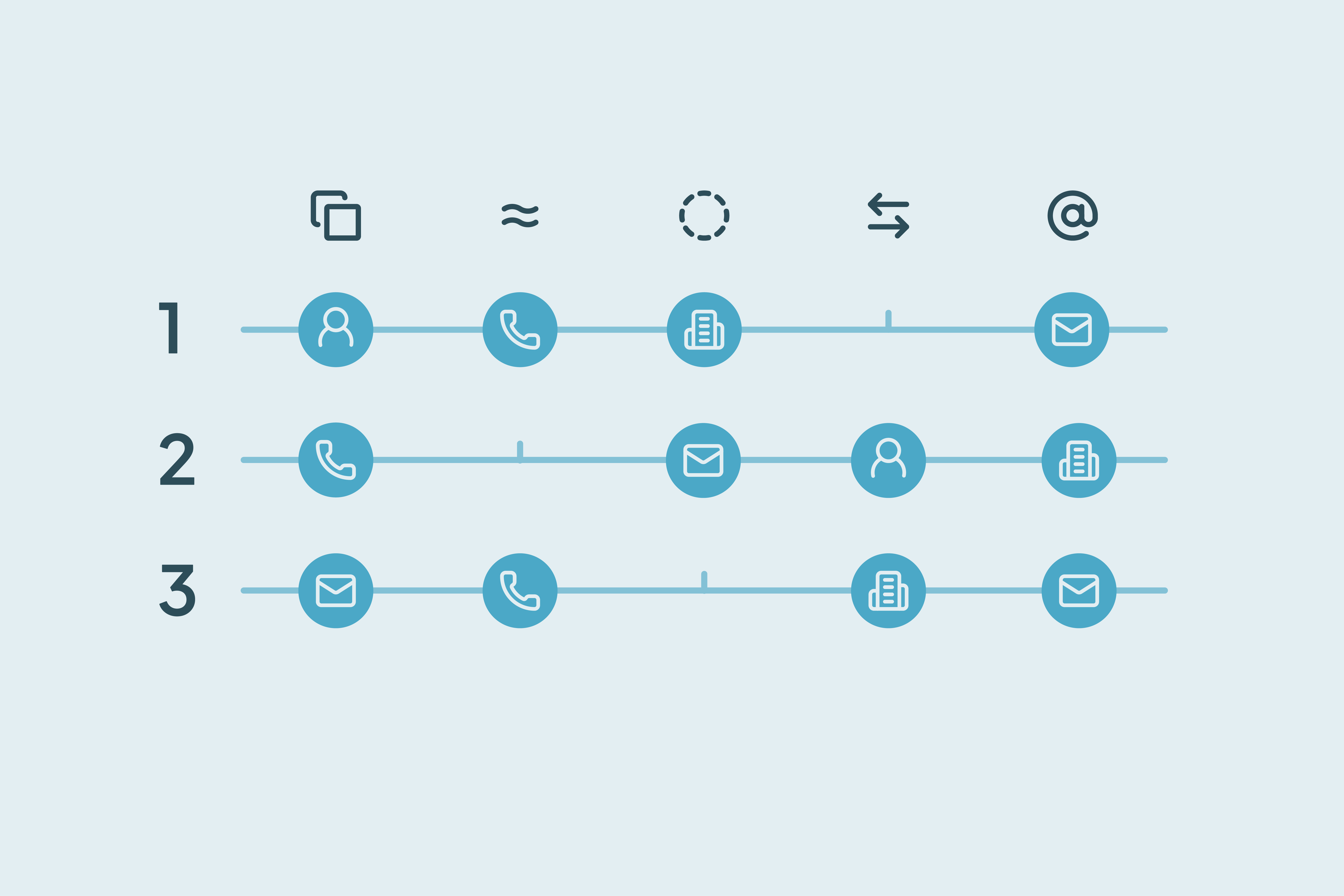
Muchos registros parecen redundantes porque comparten valores en campos obvios. Estos son los tres patrones más comunes que confunden a los equipos de CRM:
Identificadores compartidos
Registros con el mismo nombre, dominio de correo o empresa suelen marcarse como duplicados. Pero estos pueden venir de inboxes del equipo, organizaciones partner o contactos repetidos con formatos similares. Los identificadores compartidos son comunes en CRMs B2B y no siempre indican redundancia real.
Confusión basada en el rol
Dos contactos de la misma empresa pueden tener roles distintos: uno en soporte y otro en marketing. A simple vista pueden parecer redundantes, pero su actividad, propiedad y etapa del trato pueden ser completamente distintas.
Distinciones válidas
Incluso si dos registros se ven idénticos, cosas como ID, asociaciones o campos personalizados pueden indicar registros distintos y con sentido. Una lógica de combinación que ignora estos marcadores puede eliminar contexto válido y generar problemas aguas abajo en workflows y reportes. Usa la similitud visual para detectar, no para combinar; es una señal para revisar el registro, no para unirlo.
Por qué la detección de duplicados debe basarse en datos, no en cómo se ven los registros
La revisión visual manual introduce inconsistencia: lo que parece un duplicado para una persona puede no serlo para otra. Nombres, empresas y dominios pueden ser engañosos cuando se usan sin contexto. La detección basada en reglas elimina esa variabilidad usando condiciones a nivel de campo.
Los sistemas de CRM detectan duplicados evaluando campos específicos, como email, nombre y teléfono, contra condiciones predefinidas que determinan qué cuenta como una asociación, independientemente de cómo se vea el registro en la interfaz.
Las suposiciones visuales, por otro lado, crean dos riesgos:
- Primero, los equipos pueden combinar registros que no se comportan como parecen.
- Segundo, pueden desconfiar de la lógica cuando no se comporta como un revisor humano. Esto lleva a cambios innecesarios y reduce la calidad de las asociaciones.
La lógica basada en campos evita esta trampa. Dedupely permite a los equipos asignar campos de alta confianza, ajustar umbrales y previsualizar el comportamiento de coincidencias sin aplicar combinaciones automáticamente. Esto da visibilidad de por qué un registro cumple o no las condiciones de duplicación.
Qué hacer cuando el equipo reporta duplicados que no se están combinando
Cuando los usuarios dicen que "tienen duplicados", normalmente significa que están viendo similitud visual, pero no están revisando qué lógica se está aplicando.
- Empieza comparando los campos de duplicado: ¿los valores son idénticos o lo suficientemente cercanos como para considerarse una asociación? Luego revisa si los registros están vinculados a los mismos tratos, etapas u propietarios.
- Si los registros siguen viéndose similares, revisa qué campos están activos. En Dedupely, puedes agregar o eliminar campos para detección de duplicados, o ajustar las opciones de coincidencia para ser más flexible o más estricto.
- Después de actualizar las opciones de coincidencia, vuelve a correr el scan. Los resultados mostrarán si los registros califican según la lógica, manteniendo el proceso basado en datos y no en diseño.
Si esto sigue apareciendo en varios equipos, vale la pena pausar y revisar la lógica. En algunos casos, los equipos traen a un consultor de HubSpot para ayudarlos a reconstruir todo, pero validar campos, expectativas y si todos usan la palabra "duplicado" con el mismo significado suele ser suficiente.
Si buscas a un experto en HubSpot, te recomendamos a Chris Bryant.
El costo de las coincidencias falsas
Cuando las decisiones de combinación se basan en similitud visual, la confianza en el sistema se rompe:
- Los equipos empiezan a cuestionar sus reglas, asumiendo que la herramienta no funciona, o corrigen manualmente resultados que eran técnicamente correctos.
- Las coincidencias falsas pueden eliminar el contexto del contacto, vincular tratos incorrectamente o eliminar registros que nunca debieron combinarse.
Cuando la lógica de combinación es clara y se basa en reglas, los equipos recuperan confianza:
- El cumplimiento mejora.
- Las revisiones manuales se vuelven más enfocadas.
- Los reportes mejoran porque los registros están estructurados, no adivinados.
Herramientas como Dedupely funcionan mejor cuando la lógica está bien definida. La confianza viene de saber exactamente cómo se comporta la lógica, no de cómo se ven los registros.
Preguntas frecuentes sobre coincidencias visuales y duplicados
¿Por qué registros obviamente similares no se están combinando?
Porque la similitud visual no cumple con las condiciones de coincidencia. Los registros pueden diferir en algunos campos, o incluso verse iguales, pero no coincidir según la lógica.
¿Debería crear reglas basadas en nombre o empresa?
Puedes, pero deberían ser señales secundarias. Los campos de coincidencia fuertes son los que identifican de forma única a una persona u organización.
¿Cuál es la mejor forma de detectar duplicados reales?
Usa una combinación de campos que rara vez se repiten entre contactos. Prioriza estos sobre campos como nombre o empresa, que suelen compartirse y no identifican duplicados de forma confiable.
¿Aún puedo usar revisión visual en mi proceso?
Sí, como paso de revisión, no como regla. La revisión visual puede ayudar a detectar patrones, pero debe confirmarse con comparación lógica de campos.
¿Cómo pruebo la lógica de asociación antes de combinar?
Dedupely permite probar opciones de coincidencia creando o editando Search Pads y corriendo scans. Puedes ajustar campos y opciones, revisar resultados y confirmar todo antes de combinar.
Empieza con lógica, no con apariencia
Cuando los registros se ven similares, es tentador combinarlos, pero la apariencia no define duplicación. Los equipos que construyen lógica primero evitan falsos positivos, preservan registros válidos y confían en sus resultados de combinación.
Dedupely trabaja con esa estructura: comparar campos, respetar opciones de coincidencia y dar a los equipos control sobre qué cuenta como un duplicado real. ¿Listo para encontrar todos tus duplicados? Comienza aquí.
Contáctanos
Estamos listos para ayudarte a configurar Dedupely.
Escríbenos un correo
Probablemente ya sepamos la respuesta a tu pregunta 🙂
Agenda un Zoom
Ya sea que apenas estés empezando o ya estés metido hasta el fondo, contáctanos.
Descubre publicaciones de blog relacionadas
Mantente actualizado con nuestros últimos artículos e información.